Installing Splunk on AWS EC2 - Red Hat Linux
We would first need to create a EC2 instance on Amazon AWS.



Steps to Create EC2 Instance
- Login to your AWS console.
- Under Services -> Click on EC2
- Click on Launch Instance
- Choose an Amazon Machine Image (AMI). In my case case, I am using "Red Hat Enterprise Linux 8 (HVM)" that is available as free tier.
- Choose an Instance Type - General purpose - t2.micro, as this is eligible as free tier.
- Click on Review and Launch
- In the next step, it will show your EC2 instance configuration. Click on "Launch".
- Another window will open saying to "Select an existing key pair or create a new key pair". You will need to create a new key pair or choose an existing if you already have one. Key-pair file is a .pem file which is used to connect to your AWS EC2 instance using password less authentication.
- Download key pair file and Click "Launch Instances".
- Once your EC2 instance is created, you should see a page similar to the following. In my case I already had an existing instance, which is showing in stopped state and the one I just created is showing in running state.

- Click the checkbox near your instance name and click on "Connect" button.
- A new window will open showing the steps that you can follow to connect to your EC2 instance.
- Connection steps are different, based on the type of ssh client you are using. In my case I am using Putty, so I will follow the below steps:
- PuTTY provides a tool named PuTTYgen, which converts keys to the required format for PuTTY.
- We will need to convert the downloaded private key (.pem) file into .ppk format.
- Open PuTTYgen
- Under Type of key to generate, choose RSA. If you're using an older version of PuTTYgen, choose SSH-2 RSA.
- Choose Load. By default, PuTTYgen displays only files with the extension
.ppk. To locate your.pemfile, choose the option to display files of all types. - Select your
.pemfile for the key pair that you specified when you launched your instance and choose Open. PuTTYgen displays a notice that the.pemfile was successfully imported. Choose OK. - To save the key in the format that PuTTY can use, choose Save private key. PuTTYgen displays a warning about saving the key without a passphrase. Choose Yes.
- Specify the same name for the key that you used for the key pair (for example,
my-key-pair) and choose Save. PuTTY automatically adds the.ppkfile extension - Open PuTTy
- In hostname type "ec2-user@<Your-EC2-Public-DNS-Name".
- For example: ec2-user@ec2-100-26-11-32.compute-1.amazonaws.com.
- Click on connection -> SSH -> Auth
- Provide the private key (.ppk) file that you created using PuTTYgen and try connecting.
- You should be able to connect to your EC2 instance successfuly.
- Once you are logged in to your EC2 instance, you can use "sudo su -" to change your login to root user.
Modifying Security Group Inbound Rules associated with your EC2 instance
- In order to access your Splunk console from your local desktop or laptop, you will have to add some inbound rules under the security group associated with your EC2 instance.
- Under Instances, click the checkbox on the left side of your instance name to select your EC2 instance.
- In the second window in the bottom half of the screen you should see the configuration associated with your EC2 instance.
- Click on the security group name under the security groups
- In the new window, click on second tab "Inbound Rules"
- It will show you all inbound rules associated with the security group.
- Click on dropdown "Actions" and click "Edit inbound rules"
- Add a rule for "All TCP" traffic. Click on source and select "My IP". It should pick your IP by itself.
- Click Save Rules.

Splunk Installation Steps:
- You can install Splunk Enterprise on Linux using RPM or DEB packages or a tar file, depending on the version of Linux your host runs.
- In my case, I have downloaded the tar file which I will be using for the installation. Splunk installation on Linux is pretty straightforward.
- It is recommended to install splunk in /opt directory using the below command. The downloade splunk package is a linux tar file compressed using gzip. So we can use a combination of gunzip and tar commands or just a single command as mentioned below:
- tar xvzf splunk_package_name.tgz -C /opt
Start Splunk Enterprise on Linux
# cd <Splunk installation directory>/bin
./splunk start
When you start Splunk for the first time, it will prompt you to create credentials for the administrator account.
Once all the required details are provided, it should successfully start Splunk. See the screenshot below to see the successful startup messages.
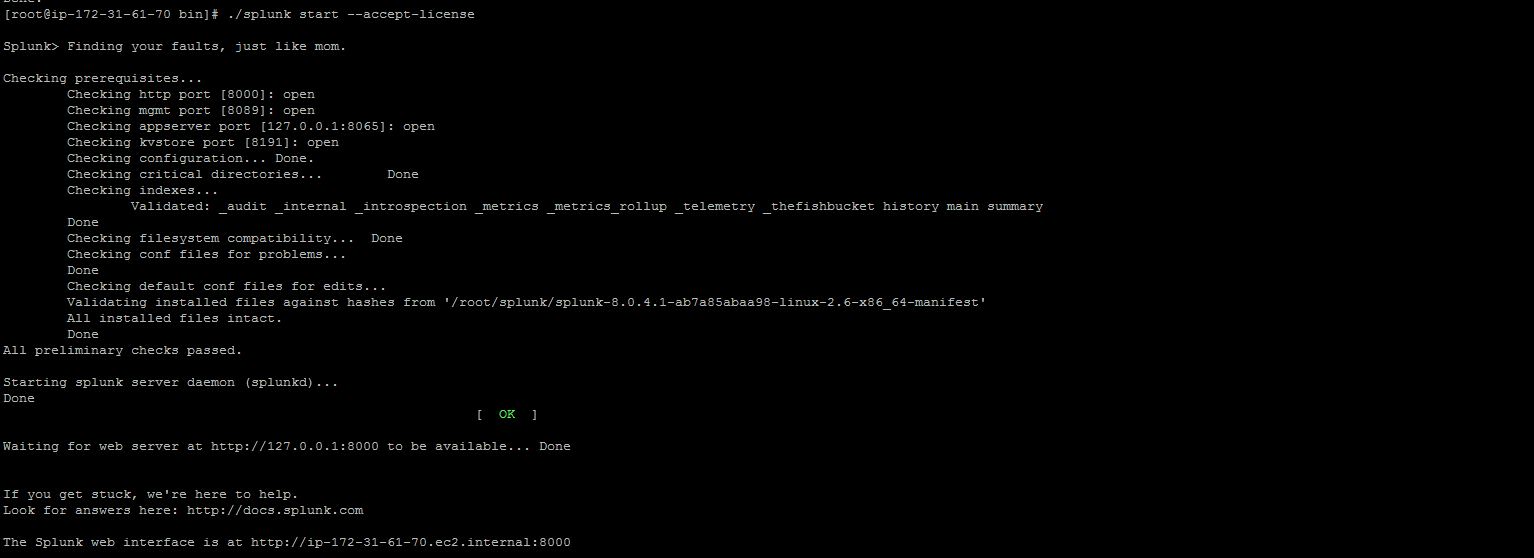
The default port to access Splunk Admin Console is 8000
You should be able to access Splunk console on below url
http://<server_name/ip>:8000

You can now ingest data to Splunk engine. There are several ways of doing it, one of the simplest way is uploading the data (.csv) file from your computer. You can refer to my blog How to upload dataset to Splunk for details on this
Comments
Post a Comment