Use Case: Let's assume that there is some process which uploads a csv file in a S3 bucket. This file contains the information about different products and their prices.



We need to create a Lambda function, which picks the file from S3 bucket as soon as it is uploaded and adds the records/items in this file to a dynamodb table.
We will use AWS Lambda service to get this working.
High Level Steps
1. Create a S3 bucket.
2. Create IAM policy and role.
3. Create DynamoDB table.
4. Create Lambda function.
5. Create Lambda Trigger.
6. Enable Cloudwatch.
7. Monitor the Lambda function execution in Cloudwatch
Detailed Steps:
- Create a S3 bucket:
Create a S3 bucket with any name. Follow my previous post for the steps to create S3 bucket. Bucket name that I have used in this example is "source-bucket104". You can use any bucket name that is not already in use.
- Create IAM Policy: Create an IAM policy which provides read access to the bucket that you created in the previous step. Follow my previous post for the steps to create IAM policy and role. You can also use JSON editor to create the policy with below policy description:

- Create IAM Role: Now goto IAM -> roles and create a new role. Attach the below policies to the role:

- The policy that was created in previous step which can read from S3 bucket.
- Existing AWS managed policy AWSLambdaBasicExecutionRole: This policy gives the lambda function privileges to write logs to AWS CloudWatch.

- Create a table in DynamoDB: There are several ways to create a table in DynamoDB, one of them being AWS CLI. You can use below command inside AWS CLI to create a new table in DynamoDB.
You can also use AWS management console -> Services -> Database -> DynamoDB -> Create Table option.
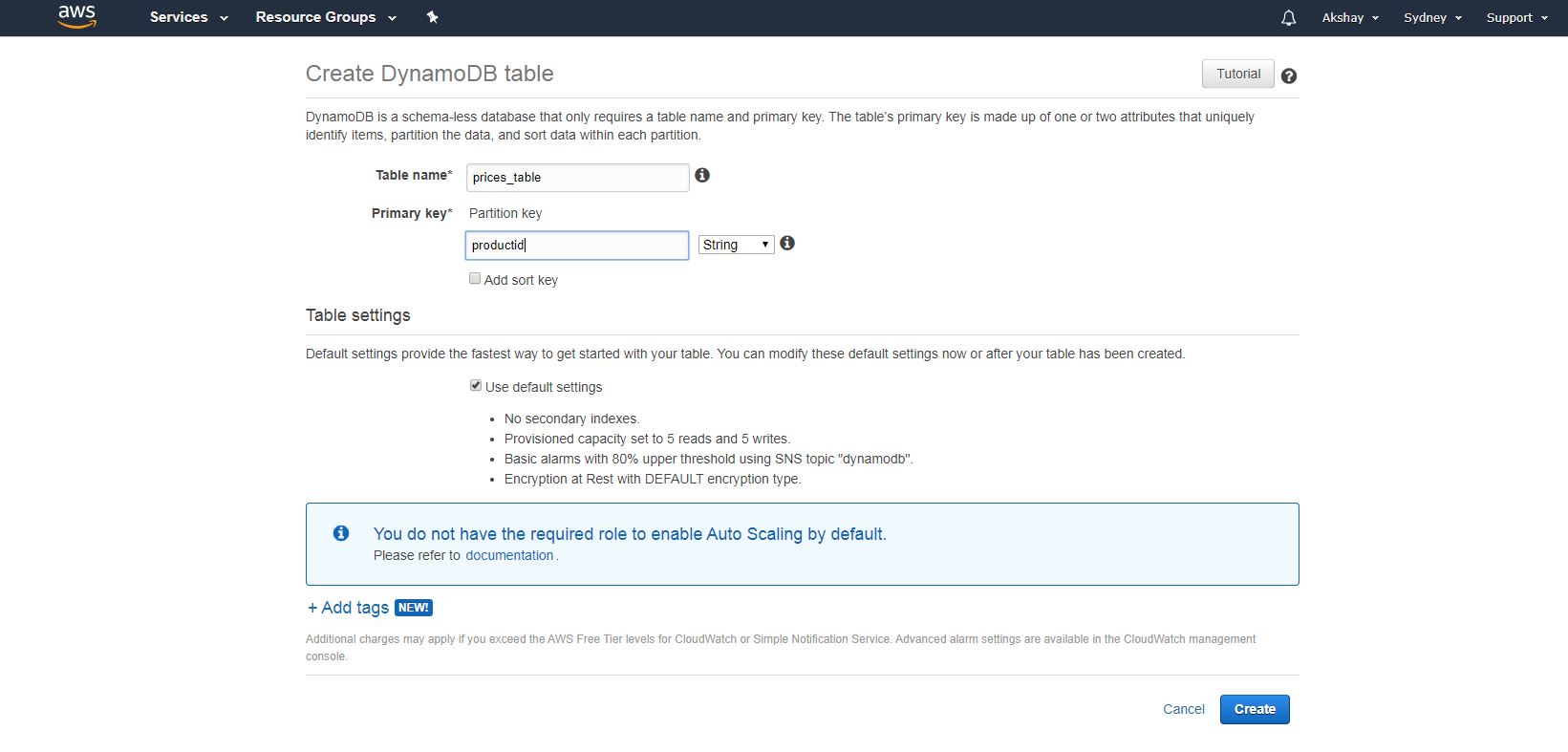
- Create Lambda Function:
- Goto Services -> Compute -> Lambda -> Create Function
- Choose a name of the function
- Provide runtime as "Python 3.8" or similar
- Under "choose the execution role", select the existing role that you created in previous steps.
- Click "Create Function"
- Enter the Lambda code provided in the link below to the "Function Code" window:
This function does the following operations:
- Reads a csv file from S3 bucket.
- Gives an error if it not a .csv file.
- Reads the file line by line
- Skips the first line of the file, assuming that it contains column header
- Splits each line using comma (,) as delimiter and stores the column values in different variables.
- Adds an item in the dynamodb table "prices_table" and returns response.
- Create Lambda Trigger. In the Lambda console, click on Add trigger and create a trigger against the S3 bucket you created in previous steps for all object create events.
- Test and Monitor:
- Now upload a csv file in S3 bucket which contains the relevant data. I have used a csv file which consists of below columns. I have used the same columns inside my function to write to dynamodb
productid,product_name,price,sale_price,code
- Goto DynamoDB > Tables
- Click on the table that you created and goto Items tab. You should see all the records in the csv file added to the table.
- To monitor the logs of lambda funtion, goto CloudWatch Service -> Logs -> Log groups -> <Lambda Function Name>
- Logs should show something similar to below if the file records were added successfully in the dynamodb table:

Comments
Post a Comment