In this article we will query data stored in S3 buckets using an interactive query service provided by AWS, i.e., Athena. We will perform below steps:










- Create a bucket in AWS S3.
- Create an external table in Athena which points to S3 bucket
- Upload csv data files to S3 bucket.
- Query data from S3 using AWS Athena service.
Login to AWS management console.
- First we need to create a new bucket inside S3. A bucket in AWS S3 is a public cloud storage. We can create a bucket and upload files using S3 API or management console.
- Click on Services -> S3 -> Buckets -> Create bucket
- On the following page provide a name for the bucket. You can use any name, but keep in mind that the bucket name should be unique among all AWS S3 buckets.
- You can select any region of your choice and click Next

- On the next screen, you can provide below information for your S3 bucket. I am not changing any values and leaving it to their defaults.
- Versioning: Versioning enables you to keep multiple versions of an object in one bucket.
- Server access logging: Provides detailed records for the requests that are made to a bucket.
- Tag: To track storage cost or other criteria.
- Object level logging: Records object-level API activity using AWS CloudTrail for an additional cost.
- Encryption: Objects are encrypted when stored in S3 using Server-Side or Client-side encryption.
- CloudWatch request metrics: Monitor requests in your bucket for an additional cost.
- On the next screen select the permissions for your bucket and click next.
- On the next screen review your settings and click on "Create bucket".
- You should be able to see your new bucket under S3 buckets. See the screenshot below. You can also view the bucket properties by selecting the bucket name.

2. Next step is to create two folders inside your S3 bucket.
- First folder to hold your csv files data which will be queried by Athena.
- Second folder to hold the output of your Athena queries.

Now go to Services -> Analytics -> Athena
- Once you are inside Athena console, the first step is to create the output location for your queries.
- Click on Settings and provide the Query result location in the below format and click "Save".
- s3://athena-test-bucket102/output-folder/

- Click on Data Sources tab -> Connect data source
- On "Choose a data source screen", leave it to default "AWS Glue data catalog" and click Next
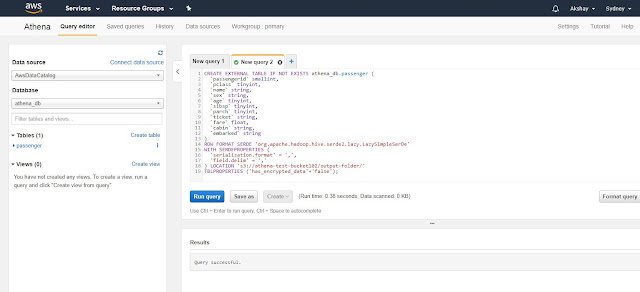
- On "Connection details" screen, select "Add a table and enter schema information manually" and click "Continue to add table".
- On the next screen, provide a new database name which will hold the table and a table name.
- The dataset I am using contains a list of passengers, so I have named my table as passenger
- We also need to provide the location of out input dataset, which is the input-folder that we created inside our bucket and click Next.

- On the next screen select the data format. As we are using a csv file, we will select "CSV" and click next.
- On the next screen we need to provide column names and their data types. We have 2 options, either add columns one by one, or add bulk columns. I am using "Bulk add columns" option and I have provided all my column names as per the data in my csv files sperated by comma. See the screenshot below. Click Add, review your column names and Click Next.

- We are not configuring any partitions for now. Click "Create table" and your table should be created. It also shows you the "create external table" command that is used to create the table. We can also use this command in order to create the table. In the screenshot below, my new table and database is displayed on the left side of the screen.

If you try to run a select statement against this table, you will not be able to see any results, as we have still not uploaded any data in the S3 bucket.
Let us upload our csv dataset.
- Go to the S3 bucket that you created and go inside the input-folder.
- Upload the csv dataset file and leave all options as default.
- Now go back to Athena and run a simple select statement and you should be able to see the results of the query.

Let's do another query to find the minimum and maximum passenger id and how many records we have in our data.
SQL: select min(passengerid) "FirstId" ,max(passengerid) "LastId",count(*) "PassengerCount" from passenger;
Query Result:
First Passenger Id: 892
Last Passenger Id: 1309
Passenger Count: 418

Now let us upload another csv file with different passenger list, in the same folder and run the same query again. In below screenshot you can see "Passenger_list2.csv" file uploaded in S33 bucket.

If we run the same query again, then we can see that athena now queries both the datasets this time and provide details from both files.
SQL: select min(passengerid) "FirstId" ,max(passengerid) "LastId",count(*) "PassengerCount" from passenger;
Query Result:
First Passenger Id: 1
Last Passenger Id: 1309
Passenger Count: 1309

As long as 로스트아크 you’re 21+ and in a state where on-line playing is legal, today have the ability to|you possibly can} guess on sport, enter day by day fantasy sports activities contests, and play on line casino games, properly as|in addition to} poker, by way of your laptop or cell. Our specialists' task at Gambling.com is to know the market inside out. We've labored with the leading US operators, been a part of} customer service teams, created the best playing instruments, and most importantly - we're experienced gamblers ourselves. So our community of reviewers can pretty evaluation and compare the best on-line casinos and sportsbooks obtainable within the US. The factor about|wonderful factor about|beauty of} about these on-line playing sites is that they're backed by state lotteries.
ReplyDelete